We propose a masking distribution‑guided test-time scaling method to improve the precision of VLAs in robotic manipulation.
Vision-Language-Action models (VLAs) excel at robot control but their single-inference, greedy-decoding paradigm bottlenecks high-precision manipulation. Existing test-time scaling approaches rely on external verifiers that require additional training and fail to generalize to unseen conditions.
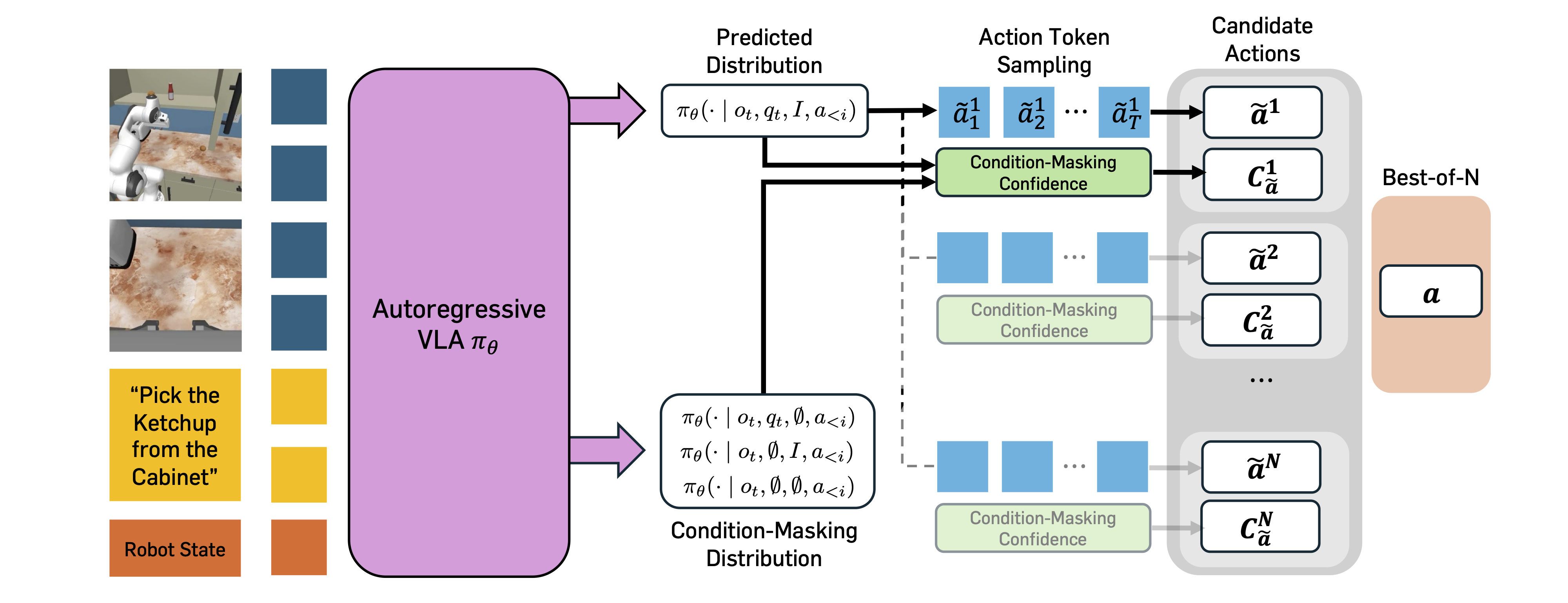
We propose Masking Distribution Guided Selection (MG-Select), a verifier-free test-time scaling framework that uses KL divergence from a condition-masking reference distribution as a Best-of-N confidence signal. The reference is produced by the same VLA with randomly masked states and language conditions. A joint training strategy that applies dropout to state and language conditions further sharpens the reference at test time.
Our experiments demonstrate that MG-Select consistently improves state-of-the-art VLAs across diverse simulation and real-world pick-and-place benchmarks, without any additional training or external module at inference.
MG-Select achieves substantial gains over greedy decoding across simulation and real-world benchmarks, without any external verifier.
1. Motivation
VLAs have shown remarkable performance in robot control, yet they remain fundamentally limited on tasks that demand high precision. Even after extensive pre-training, they often fail on fine-grained manipulation such as grasping or object placement. This precision gap is especially problematic for real-world applications where millimeter-level accuracy can decide task success.
A natural remedy, inspired by Test-Time Scaling (TTS) in LLMs, is repeated sampling + Best-of-N selection. Prior work pairs sampling with an external verifier trained via reinforcement learning on robotic data, which introduces two significant drawbacks: (i) it adds substantial training cost and deployment complexity, and (ii) the learned verifiers fail to generalize to unseen task prompts or objects, limiting broader applicability.
Our goal is therefore a TTS framework that leverages the model's internal properties, with no extra training and no external modules.
2. Condition-Masking Distributional Confidence
Naive likelihood-based Best-of-N often fails because VLAs fine-tuned on the target task produce overly concentrated action token distributions, causing multiple samples to collapse to the same action. Instead, we compute a confidence score via the KL divergence between the predicted distribution and a reference distribution that represents uncertainty. Intuitively, actions that deviate most from an uncertainty-aware reference are the most confident.
We build that reference using the same VLA, but with specific input modalities masked, approximating failure modes where essential conditions are ignored. We consider three variants:
Token-wise KL is aggregated into an action-level confidence $C_{\tilde{a}} = \sum_{i \in \mathcal{I}} \mathrm{KL}(Q_i \,\|\, P_i)$, and the final action is selected via Best-of-N:
The optimal masking variant depends on the environment: state-masking works best on benchmarks that are single-task pick-and-place (e.g., SIMPLER-WidowX), while text-masking dominates on multi-task environments (e.g., RoboCasa) where instructions are indispensable.
3. Joint Training Strategy
Standard VLAs are not trained to see masked inputs, so directly feeding a masked condition yields degenerate distributions. We augment fine-tuning with all four masking variants:
Dropout over $q_t$ and $I$ is applied during training. The resulting VLA, denoted MG-Select*, matches standard-fine-tuning performance and produces meaningful condition-masking references at test time, yielding a stronger confidence signal and further amplifying MG-Select's gains.
MG-Select produces high-precision actions at the critical moments, grasping and releasing, where the base policy often fails.
Real-world "Box to Bowl" task on the Franka Research 3.
Since MG-Select generates $N$ candidate actions in parallel, a naive implementation repeats the expensive prefill step $N$ times. This is particularly critical for VLAs, which re-prefill at every timestep to condition on the current observation.
We design a single-prefill deployment that shares one prefill across all $N$ candidates before decoding. With $N=4$, this gives a 45% latency reduction compared to vanilla MG-Select, keeping inference time comparable to single-action inference across different candidate sizes.
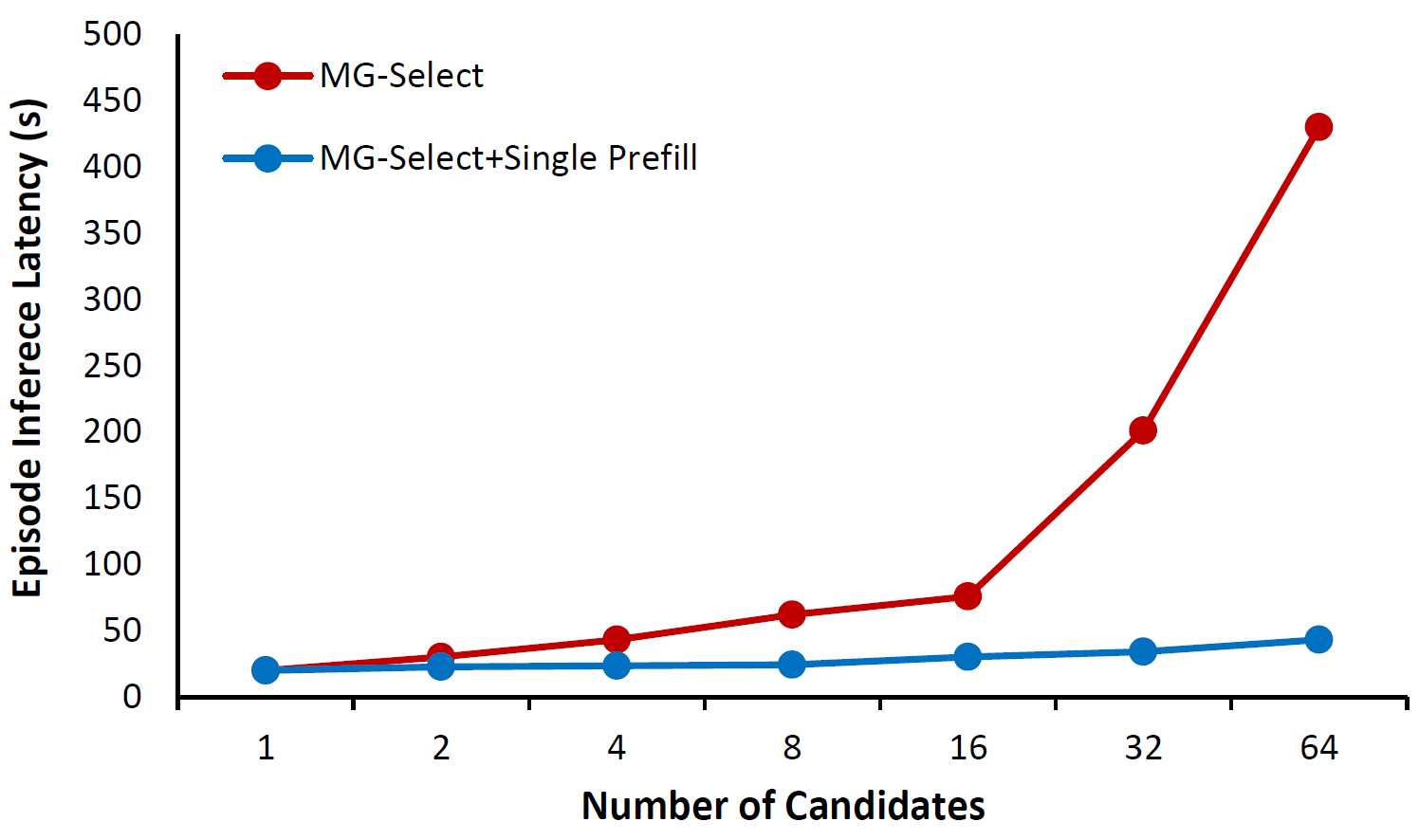
Table 5 (b). Effect of candidate count $N$ on RoboCasa (100 demos). Gains saturate quickly, and $N=4$ already captures most of the improvement.
| $N$ | PnP | All |
|---|---|---|
| 1 | 27.6 | 43.8 |
| 2 | 30.0 | 46.2 |
| 4 | 31.0 | 48.1 |
| 8 | 30.0 | 46.9 |
| 16 | 30.7 | 46.1 |
| 32 | 31.0 | 46.6 |
| 64 | 33.3 | 48.4 |
MG-Select consistently improves state-of-the-art VLAs across simulation, real-world Franka experiments, a real-to-sim evaluation, and a long-horizon zero-shot benchmark, all without any external verifier.
| Model | 30 Demos | 100 Demos | 300 Demos | |||
|---|---|---|---|---|---|---|
| PnP | All | PnP | All | PnP | All | |
| GR00T N1 | 0.4 | 17.4 | 2.2 | 32.1 | 22.6 | 49.6 |
| π0-FAST† | 5.3 | 30.9 | 17.0 | 40.2 | 43.2 | 61.2 |
| + MG-Select | 7.2 | 32.0 | 22.6 | 43.7 | 46.5 | 61.3 |
| + MG-Select* | 14.2 | 34.6 | 31.0 | 48.1 | 46.9 | 62.9 |
* denotes additional joint training before test-time scaling.
Table 4. In-distribution: 60 demos per task, 24 trials (4 objects × 6 trials) per task.
| Model | Box→Bowl | Box→Plate | Basket→Bowl | Plate→Basket | Avg. |
|---|---|---|---|---|---|
| π0-FAST-DROID | 41.7 | 37.5 | 45.8 | 25.0 | 37.5 |
| + MG-Select* | 58.3 | 54.2 | 50.0 | 29.2 | 47.9 |
* denotes additional joint training before test-time scaling.
Table 3. Out-of-distribution: unseen objects, 16 trials per task.
| Model | Pick up Tape | Take Cup out of Bowl | Avg. |
|---|---|---|---|
| π0-FAST-DROID | 56.3 | 50.0 | 53.1 |
| + MG-Select | 68.8 | 75.0 | 71.9 |
| Model | Spoon on Towel | Carrot on Plate | Stack Cubes | Eggplant in Basket | Avg. |
|---|---|---|---|---|---|
| RT-1-X | 0.0 | 4.2 | 0.0 | 0.0 | 1.1 |
| Octo | 12.5 | 8.3 | 0.0 | 43.1 | 16.0 |
| RoboVLM | 29.2 | 25.0 | 12.5 | 58.3 | 31.3 |
| SpatialVLA | 16.7 | 25.0 | 29.2 | 100.0 | 42.7 |
| π0-FAST† | 66.7 | 70.8 | 41.7 | 8.3 | 46.9 |
| + MG-Select* | 69.4 | 75.0 | 43.1 | 13.9 | 50.3 |
* denotes additional joint training before test-time scaling.
| Model | Task | Tasks Completed in a Row (%) | Avg. Len (↑) | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| π0-FAST† | ABC→D | 96.0 | 85.8 | 74.4 | 62.4 | 50.6 | 3.69 |
| + MG-Select* | ABC→D | 96.9 | 88.0 | 77.8 | 67.6 | 55.8 | 3.86 |
* denotes additional joint training before test-time scaling.
@inproceedings{jang2026verifierfree,
title = {Verifier-free Test-Time Sampling for Vision-Language-Action Models},
author = {Suhyeok Jang and Dongyoung Kim and Changyeon Kim and Youngsuk Kim and Jinwoo Shin},
booktitle = {The Fourteenth International Conference on Learning Representations},
year = {2026},
url = {https://openreview.net/forum?id=UD4Rw8MOEK}
}